- Simple AWS
- Posts
- Event-Driven Architecture in AWS: Basic Concepts
Event-Driven Architecture in AWS: Basic Concepts
Guille Ojeda
May 05, 2024
Event-Driven Architecture (EDA) is a software architecture pattern that consists of having application components communicate using asynchronous events. Since components don't need to know where they are sending information or where the information they're consuming comes from, this effectively decouples each application component from the upstream and downstream behavior of the system. And it also introduces significant complexity.
This article is part 1 of a series that will help you understand the Event-Driven Architecture pattern, with two objectives: Understanding why you most likely don't need it, and having fun reading about complex stuff. In this part, we'll focus on the core concepts of Event-Driven Architectures. The next parts will be published in the coming weeks.
Introduction to Event-Driven Architectures (EDA)
Event-driven architecture (EDA) allows application components to be loosely coupled and communicate through events. In an event-driven architecture, components execute behavior in response to events generated outside of them. These events could be a user’s action, changes in data, or a message sent by another process, for example upon completion or failure.
In an EDA there is no central system specification for end-to-end system behavior. Instead, the complete behavior of the system can be expressed as a collection of if..then rules: If a payment is completed, send the corresponding invoice. In any real-life implementation that collection is going to be really big, and so intractable that we tend to consider end to end behavior as an emergent property of the system, even after having intentionally programmed it.
Events That Drive the System
In an event-driven system, an event is a piece of information that describes a change in the state of the system, or an occurrence that is of interest to the system or a part of it. Events can be clicks, HTTP requests, messages in a queue, updates in a database, time occurrences, or anything that either reflects the state of the system or that the system can listen to (sometimes both).
That definition begs the question, is my app that responds to a click and an HTTP request an event-driven system? And the answer is that technically it might be. But that's not a useful way to think about it. The real distinction comes from whether your app treats these requests as a message that has a clear to: and from:, or as an event that can be listened to by any component of the system, with the sender having no knowledge of the recipients, and the recipients no direct knowledge of the sender.
You might argue that if a recipient depends on a specific message format and even contents, then it is depending on the sender, at least indirectly. In reality, the recipient is depending on the sender's ability to write a message that matches the recipient's API (protocol, headers, contents even), but it has no knowledge of the identity of that sender. There is no way to send a response to an event, both because there is no direct way to address a given component, and because the concept of a response doesn't even exist. No instance of any component ever has any knowledge of any other instances or components. Each component just does its job when an event prompts it to, and throws over its shoulder any messages it produces, with not a thought or care about who receives it (if anyone), and what happens with the rest of the system (if anything).
How Long Have Event-Driven Architectures Been Around?
The concept of event-driven architectures has actually been around since the previous century. Google, Amazon and Ebay were amongst the first to adopt it for very large scale usage, or at least the first to gain popularity for it. As the industry keeps looking for ways to build applications that are more responsive, scalable, and flexible, we've found ourselves going back to this concept again and again. And, sadly, misusing it again and again.
The rise of microservices had a huge role to play in the popularity of the EDA pattern, since the ideas behind an event-driven architecture fit really well with interconnecting microservices and letting vertical features emerge from service interactions. To be clear, they are not the same, and neither is a requirement for the other. They just fit pretty well.
Another aspect that heavily influenced the popularity of event-driven architectures is the number of organizations that suddenly found themselves dealing with massive amounts of data, especially from last decade's surge of IoT devices and the ideas around Big Data (a keyword that we haven't heard in a while).
Finally, the upgrade of serverless from "just a fad" to "production-ready" brought with it serverless event-driven architectures that were no longer considered a fun project (well, they are fun, but they're also serious and seriously useful).
Key Concepts of the Event-Driven Architecture Pattern
The event-driven architecture pattern is built upon several key concepts that we need to understand, beyond the general idea and philosophy.
The event-driven architecture model
We're used to application components having clearly defined rules for calling other components. Component A does its thing, then calls Component B which does its other thing that should naturally follow A's thing. For example, the Payments component finishes processing the payment for the order, and it tells the Billing component to create an invoice for the purchase. Note that I'm using "component" to mean a discrete part of the system, which could be something as simple as a class or as complicated as a microservice.
In an event-driven architecture, components don't directly call other components. Instead, they emit events relaying the status change of the system, and other components react to those events. In our payment -> invoice example, the Payments component would post a message to a queue saying "payment completed for order X", with no knowledge of the following steps or of which components are consuming from that queue. The Billing component is subscribed to the queue, it reads the message and generates the invoice for order X, with no knowledge of who posted that message.
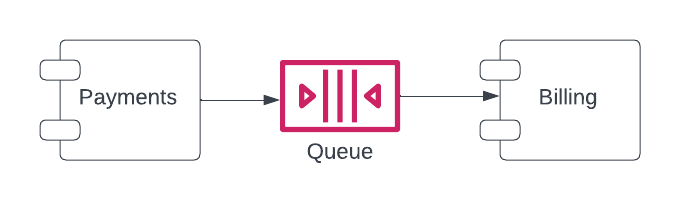
Payments publishes a message to a queue, Billing consumes it from the queue
Note that when I say "with no knowledge" I mean "with no dependencies", which is what we actually care about.
Events, Event Producers, and Event Consumers
Let me give you a more formal definition:
Events: Events represent a change in the state of the system or of any of its parts, or an occurrence in the system, for example a payment finishing its processing. Events carry data that describes the change or occurrence, for example the amount paid in said payment.
Event Producers: Event producers are responsible for generating events and publishing them. Any component within the system can be an event producer.
Event Consumers: Event consumers subscribe to events and perform actions based on the event data. Any component within the system can be an event consumer.
Loose Coupling: The key point of an EDA is that event producers and consumers do not need to have direct knowledge of each other, allowing for independent scalability, more flexibility, and stricter modularity within the system.
Any component can be an event producer and an event consumer. The role of producer and consumer is relative to a specific event, where we conceptually distinguish the two components to better reflect on the loose coupling between them. Additionally, it is a useful distinction for saying that a component is an event consumer of this and that event, and a producer of this other event. For a given event, such as a payment being processed, listing all of its consumers is useful in understanding all the things that will happen next. But please understand that this distinction does not limit the role of components in any way, and any component can be a producer or a consumer of any event.
Elements of an Event-Driven Architecture
The only things you actually need for an event-driven architecture are components (at least 2), events, and a way for those events to reach those components. Two serverless functions and a queue are, in fact, an event-driven architecture. But let's consider a system that's a bit more complex, and more interesting.
These are all the types of elements that you can find in (or fit into, I guess) an event-driven architecture:
Components: This is your average, friendly neighborhood service or module. It can produce events and consume events, and often does both. Your code goes here.
Events: They're the messages that trigger components to do stuff. They'll at least have a type of event (e.g. "PaymentProcessed"), a source (which component emitted it), and a timestamp. They often carry some additional information, such as the OrderId and the amount in our
Payment -> Invoiceexample.Event buses: This is the communication mechanism that routes events from event sources to the appropriate listeners. Message brokers, queues, and publish/subscribe topics are common event buses. Some event-driven architectures will have a centralized event bus to which every component is subscribed. In those cases, every component gets every message, and it's the job of each component to determine whether or not they need to do something about that event. Other event-driven architectures have different event buses for different message types, for message domains (like the domains in Domain-Driven Design), and/or for message tiers (Service-Oriented Architecture does this).
Data stores: Any place where data is stored persistently, such as a database. Some databases, like Amazon DynamoDB, can also fire events when operations are performed. For others, tools have been created to achieve that.
Cron events: Not every event comes from a system component. Cron events come from Time Itself, which is an ominous and poetic way of saying they're events that happen at a certain time interval, like every day at 4 am.
How data is processed in event-driven architectures
A key point that you might have gleamed from my explanations is that event-driven communication is asynchronous. This means that when Component A "calls" Component B, it doesn't get blocked waiting for Component B to finish. Instead, Component A publishes an event on an event bus to which Component B is subscribed, Component B receives the event, determines what it needs to do (which could be nothing), and does that. If Component B wants to notify Component A that it finished, it'll need to publish a new event that says "Action B finished". Component A, in turn, should be subscribed to the event bus, and will get notified of the event that Component B just published.
It sounds like a really convoluted way of doing (new ComponentB()).doThing(X), right? Well, it kind of is. But we're not just solving Component A calling Component B. We're also:
Letting Component A keep doing its own thing while Component B does whatever it needs to do with that message instead of blocking itself and waiting idle. This is called asynchronous processing, and it's not exclusive to EDA.
Allowing for other components to do something when Component A publishes "X", or when Component B is done with "X", without needing to change anything in either Component A or Component B.
Adding mechanisms to handle what happens when Component B fails while in the middle of processing "X".
Decoupling Component A from Component B.
I keep insisting on that last one, Decoupling, because it really is the key here. To cement that idea, let's think about how Component B would let Component A know that it's done. The answer is that it can't. It's completely impossible for Component B to tell Component A anything whatsoever. What Component B can do is publish a message saying "I'm done", and that's it. Component A will either be listening for that message and do something about it, or it won't be listening. Whatever Component A needs to do in response to Component B finishing, and whether it succeeds or not, does not and should not be a concern for Component B. They are decoupled, not just at the implementation level (meaning their code is separate), not just at the deployment level (meaning they're deployed separately and can scale independently), but at the responsibility level. Component B is not responsible for whatever Component A did before sending the first message, or for whatever Component A does after receiving Component B's "I'm done" message, or for which other component does whatever. It simply receives a message, does its thing, and publishes a message saying it did its thing.
Differences Between Event-Driven Architectures and Microservices
Is every component in an event-driven architecture a microservice?
Not necessarily. They could be, but they don't need to. It does mean, however, that each component performs a specific task, and is decoupled from other components. This results in a loosely coupled system, where changes to one component do not affect the functionality of other components.
So… microservices?
No! What makes a service a microservice is the definition of a bounded context around the service and its data. Process A can call Process B through HTTP (the most common option), gRPC (an alternative), a shared event bus (event-driven architecture), a queue (again, event-driven architecture), database events (still event-driven) or through smoke signals if they can understand that; but that fact alone doesn't make them microservices.
If Service A communicates with Service B only through an event bus, but they both access the same database, then they are event-driven, but they're not microservices. On the other hand, if each service manages its own data, which can only be accessed via the service's API (this is what we call a bounded context that includes the service and the data), but they communicate synchronously via HTTP, then they are microservices, but they are not event-driven.
Here's a great (in my humble opinion) read about Microservices in AWS.
Loose Coupling in Microservices and Event-Driven Architectures
Both architecture patterns will result in loose coupling. But the coupling that they loose is across different concerns, or different reasons for changing. Converting your monolith into a modular monolith will decouple your components from implementation details, meaning the internal code of one can change without requiring that others change. Converting that into distributed services will decouple them from deployment details, meaning the way a component is deployed can change (e.g. it can scale horizontally) without requiring that others change. Converting those distributed services to microservices will decouple them from domain details, meaning that domain concepts that are internal to a microservice's bounded context can change (e.g. a new column can be added to a database) without requiring that other microservices change.
Event-driven architecture also results in loose coupling, but it's not across implementation details, but across interactions. A perfectly designed microservice A may call upon another perfectly designed microservice B, and even changing microservice B's database from Amazon RDS to DynamoDB won't make microservice A change. But what happens if we want to add a completely new thing that should happen after microservice A executes an action? We'll have to change micoservice A's code to add a call to our new microservice C. The implementation details of microservice C don't matter at all, our microservices architecture protects microservice A from that. But its mere existence, and the fact that it needs to do something after microservice A did something else, is a reason for microservice A to change.
With an event-driven architecture, microservice A will never call either microservice B or microservice C. All it will do is publish an event to an event bus, and microservice B will be subscribed to that bus, will receive that event, and will do its own thing. When we add microservice C, all we need to do is subscribe it to the same event bus as microservice B, and it will receive a copy of the same event, without us having to change microservice A. We're in the presence of event-driven microservices.
That makes it sound like the best of all worlds is event-driven microservices, and that's what we should be doing in every project. Please, just don't. Both patterns loose the coupling of your components across different concerns, but add significant complexity in doing so. You're making your software easier to change in some aspects, but significantly harder to understand as a whole. For most projects, neither pattern is worth the added complexity, and both patterns at the same time is usually what we call resume-driven development: just doing things that will look good on your resume.
To recap, these are the coupling concerns we just discussed, and the patters that loosen them:
Implementation details: Modules, or a modular monolith
Deployment details: Distributed services
Domain details: Microservices
Behavior of the rest of the system: Event-driven architecture
The best way to understand the difference is with an example, so I recommend you read Monolith vs Event Driven Architecture with an Example when you have the time. A microservices implementation would look a bit different from the monolith I discuss there, but the concepts leading to the flow of data in that monolith can also be applied to microservices, the main difference would be the separation of concerns and deployments.
AWS Services That Enable Event-Driven Architectures
Alright, that was a lot of theory. How does that relate to AWS? AWS has several services that can act as event buses, and deciding which to use will depend on understanding the specific requirements for the events that you're going to use, and the characteristics, strengths and limitations of each AWS service. In this section I'll focus on the latter.
Amazon SNS and Amazon SQS for Messaging
Amazon SNS (Simple Notification Service) and Amazon SQS (Simple Queue Service) are two different messaging services. SNS acts as a one-to-many bus, implementing the publish/subscribe architecture pattern. Consumers subscribe to a topic, and when a publisher publishes a message to that topic, each subscriber will get a copy of that message. Here's a great example on how to use Amazon SNS to decouple components in an architecture. An important aspect is that messages aren't stored in an SNS topic, they're delivered immediately and then deleted. It's each subscriber's job to be available to handle them.
SQS, on the other hand, provides you with a managed queue. In a typical implementation, publishers publish messages to the queue and the messages sit there, waiting until a consumer actively polls the queue asking whether there are new messages. When that happens, the queue delivers a message to that consumer, and deletes the message from the queue. Then, that consumer, or any other consumer, can poll the queue for the next message stored there. This results in each message being read only once, but has the advantage that the queue will hold the messages until consumers are available to handle them. Here's an example on how to use an SQS queue to throttle database operations.
You can combine SNS and SQS, for example to have a single message delivered to multiple queues, where it can wait for different types of consumers. This is called a fan-out pattern, because you create copies of the message that will be handled differently downstream.
AWS Lambda for Serverless Event Handling
AWS Lambda is a serverless computing service that allows the execution of code in response to events. The key detail here is that those events can be your typical HTTP request handled by a backend server (in which case you're just replacing a typical server like an EC2 instance with a serverless option), or they can be any event in an event-driven architecture.
AWS Lambda can be combined with many other AWS services that emit events, such as DynamoDB Streams, or S3 Events. Additionally, its integrations are designed to be easy to use, for example if you configure a Lambda function to be triggered by an SQS queue, the AWS Lambda service will actively poll the queue behind the scenes, and only execute your code (and only bill you) when there is a message in the queue.
Amazon Kinesis for Real-Time Data Streaming
Amazon Kinesis is a fully managed AWS service that enables real-time data streaming at scale. It allows the ingestion, processing, and analysis of streaming data from various sources, where producers write to a Kinesis Data Stream, and messages there can be polled by consumers at any point in time during the time that the message is kept in the stream (a pattern called rolling window).
In event-driven architectures, Amazon Kinesis can be used to collect a large volume of events from event producers, and allow consumers to read from them at scale. Naturally, it also integrates really well with other AWS services. For example, AWS Lambda can subscribe to a Kinesis data stream to receive all messages. Moreover, you can configure Kinesis data streams to send the data to an S3 bucket for storage and auditing.
Conclusion
In conclusion, event-driven architectures mean you need to rethink how system components communicate, and how you conceptualize the flow of data in your system. The key point is that you're decoupling each component from the behavior of the system. That means each end-to-end use case of the system is a particular combination of some components, called in a specific sequence. After everything is implemented you might argue that it's not that different, all you're doing is putting an SNS topic between two components. But the conceptual difference plays a significant part when architecting the system, and especially when designing changes to the system.
This article dealt with the base concepts of event-driven architectures. Stay tuned for the next article in this series about event-driven architecture.
Did you like this issue? |
Join the conversation